Doç. Dr. Özgür Baştürk
Ankara Üniversitesi, Astronomi ve Uzay Bilimleri Bölümü
obasturk at ankara.edu.tr
http://ozgur.astrotux.org
Bu derste neler öğreneceksiniz?¶
Yapılandırılmş Sorgu Dili SQL¶
- Python ve SQL
- SQL ile Tablo Oluşturma
- Veritabanıyla Bağlantının Kurulması
- Veritabanı tablolarına verinin alınması
- SQL Sorgularıyla Satır Seçme
- Şartlı Sorgular
- Bir Veritabanının Yapısının İncelenmesi
- Örnek 3: Onaylanmış Küçük Gezegenler
- SQL'de Veri İstatistikleri ve Birleştirme Fonksiyonları
- Sorgu Sonuçlarını Sıralama ve Limitleme
- Örnek 4: Gezegen İstatistikleri
- Veriyi Gruplama
- Kaynaklar
Python ve SQL¶
Giriş ve Gerekli Paketlerin Kurulumu¶
Yapılandırılmış Sorgu Dili - SQL ilişkisel (ing. relational) bir veritabanı yönetim sisteminde (RDBMS) tutulan verileri yönetmek için tasarlanmış, veritabanı yönetimi ve sorgulanmasına özgü olarak geliştirilmiş bir dildir. Öncüllerinden farklı olarak tek bir komutla birçok kayda erişme imkanı sağlaması ile öne çıkmış ve o zamandan beri de veritabanı alanında bir standart olarak kullanılagelmiştir. Kendisi bir programlama dili olmayıp, veritabanlarını sınırlı bir programlama kapasitesi sağlayan komutlar üzerinden yönetme ve sorgulama olanağı sağladığı için genellikle ve yanlışlıkla bir programlama dili sanılır.
Bu derste temel SQL komutlarını python dilinin olanaklarıyla birleştirmek üzere yapılandırılmış sorgu diline dayalı, açık kaynak kodlu bir veritabanı yönetim sistemi olan PostgreSQL kullanılacaktır. Bu nedenle ilgili kodların çalışması için makinenizde bir PostgreSQL sunucusunun kurulu olması ya da bağlanabileceğiniz bir PostgreSQL sunucusunun varlığına ihtiyaç duyar. Kurulum için bkz.. Ubuntu gibi bir Linux tabanlı işletim sisteminde PostgreSQL kurulumu için apt uygulaması aşağıdaki şekilde kullanılabilir.
sudo apt install postgresql postgresql-contrib
İstendiği takdirde MySQL gibi yine SQL'e dayalı bir başka veritabanı yönetim sistemi de tercih edilebilir.
Ayrıca PostgreSQL-Python etkileşimi için pyscopg2 modülü kullanılacaktır. Ancak öneri psycopg2-binary kurulması yönündedir; zira 2.8 sürümü sonrası psycopg modülünün isminin değişmesi planlanmıştır. Her iki modül de pip ya da başka bir "installer" ile kolaylıkla kurulabilir. Bu amaçla yazılmış başka modüller de bulunmaktadır. Ayrıca sqlalchemy araçlarından da faydalanmanız gerekebilecektir. Python-SQL etkileşimi için sqlalchemy modülünün kurulu olmasında da fayda bulunmaktadır.
Bu derste yazılan kodların çalışması için
- Python > 3
- PostgreSQL > 9
- psycopg2-binary
- sqlalchemy
sürümlerine ihtiyaç duyulur. Ayrıca bir şifresini bildiğiniz bir de PostgreSQL kullanıcısı gerekir.
Sisteminize PostgreSQL veritabanı yönetim sistemini kurduktan sonra aşağıdaki basit komutlarla myuser isminde bir kullanıcı tanımlamanız, mydatabase isminde bir veritabanı oluşturmanız durumunda bu Jupyter defterindeki bütün uygulamaları çalıştıramnız mümkün olacaktır. Bu amaçla terminal ekranından PostgreSQL sunucunuza bağlanmanız ve gerekli komutları sırayla vermeniz yeterli olacaktır.
sudo -u postgres psql
postgres=# create database mydatabase;
postgres=# create user myuser with encrypted password 'PostGRE:sql';
postgres=# grant all privileges on database mydatabase to myuser;
Bu derste bu kullanıcı adının myuser olduğu varsayılmıştır. Bu kullanıcıyla sunucuya bağlanıp mydatabase isimli veritabanına aşağıdaki şekilde de erişilebilir.
psql -U myuser -W
...
# \c mydatabase;
\d;
Modüllerin Yüklenmesi ve Veritabanı Sunucusuna Bağlanma¶
Öncelikle ders boyunca kullanılacak modüllerin yüklenmesi gerekmektedir.
import os
import sys
# import the connect library for psycopg2
import psycopg2
import pandas as pd
import numpy as np
from sqlalchemy import create_engine
import matplotlib.pyplot as plt
Ardından veritabanı sunucusuna pyscopg2 fonksiyonları ile bağlanmak için gerekli fonksiyon connect aşağıda verilmiştir. Bu fonksiyonun argümanı conn_params_dic sözlük yapısında bağlantı ile ilgili kullanıcı adı (user), şifre (password), sunucu (host) ve veritabanı adı (database) anahtarlarının karışılığı olan değerlerini içermelidir. psycopg2.connect fonksiyonu bu parametreleri kullanarak veritabanı sunucusuna bağlanır. OperationalError bu bağlantının gerçekleşmemesi durumunda bir hata mesajı üretir ve bağlantı None türünde döndürülür. Aksi takdirde bağlantının gerçekleştiğine dair bir mesaj kullanıcıya bildirilir ve bağlantı nesnesi döndürülür.
# Define a connect function for PostgreSQL database server
def connect(conn_params_dic):
conn = None
try:
print('PostgreSQL sunucusuna baglaniliyor ...........')
conn = psycopg2.connect(**conn_params_dic)
print("Baglanti basarili..................")
except OperationalError as err:
# passing exception to function
show_psycopg2_exception(err)
# set the connection to 'None' in case of error
conn = None
return conn
Bağlantı hatası durumunda hatanın türü ve hatayla ilgili bilgiler kullanıcıya verilmelidir ki kullanıcı buna göre bir çözüm arasın. Bu amaçla aşağıda sys.exc_info() fonksiyonuna dayalı olarak yazılan hata yönetimi fonksiyonu show_psycopg2_exception fonksiyonu verilmiştir. Bu fonksiyonun argümanı psycopg2 tarafından başarısız bağlantı denemelerinde üretilen error nesnesidir.
# Define function to catch exception
# Define a function that handles and parses psycopg2 exceptions
def show_psycopg2_exception(err):
# get details about the exception
err_type, err_obj, traceback = sys.exc_info()
# get the line number when exception occured
line_n = traceback.tb_lineno
# print the connect() error
print ("\npsycopg2 ERROR:", err, "on line number:", line_n)
print ("psycopg2 traceback:", traceback, "-- type:", err_type)
# psycopg2 extensions.Diagnostics object attribute
print ("\nextensions.Diagnostics:", err.diag)
# print the pgcode and pgerror exceptions
print ("pgerror:", err.pgerror)
print ("pgcode:", err.pgcode, "\n")
SQL ile Tablo Oluşturma¶
SQL'de tablo oluşturmak için CREATE TABLE table_name komutu kullanılır. Bu isimle aynı veritabanında kayıtlı bir tablo varsa öncelikle onu silmekte fayda olacaktır. Bu amaç için DROP TABLE IF EXISTS table_name komutu kullanılır. Her iki SQL komutunu çalıştırmak için psycopg2.connection.cursor nesnesinin execute fonksiyonu kullanılmalıdır. Bu fonksiyona çalıştırılmak istenen SQL komutu SQL'de çalışacağı şekilde metin yapısında geçirilmelidir. Bu amaçla ilgili komuta python nesnelerinden girdi alınıyorsa bu girdiler yer tutucularla metin içine yerleştirilerek execute fonksiyonuna gönderilmelidir.
NASA Kepler Ötegezegen Veritabanı Uygulaması¶
Bir veritabanı, organize edilmiş (genellikle yapılandırılmış) bir veri topluluğudur.
Bu derste örnek olarak NASA ötegezegen arşivinden alınan Kepler keşfi bir grup yıldız ve bu yıldızların etrafında keşfedilen gezegenler hakkında bilgileri içeren sırasıyla Star ve Planet adlarında iki tablodan oluşan bir veritabanı oluşturulmak istenmektedir.
Aşağıdaki şekilde, bu tabloların organizasyonu görülmektedir.
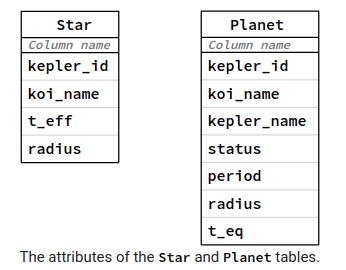
Aşağıda bu organizasyona uygun olarak Star tablosunu:
kepler_idboş bırakılamayacak (NOT NULL), tamsayıdan oluşan (INTEGER) nesnelerle tanımlanan Kepler katalog ID'leri,koi_name20 karakter uzunluğunda metin veri saklayabilecek (VARCHAR(20)) Kepler kataloğu nesne isimlerini,t_efftamsayı olarak tanımlanacak yıldız etkin sıcaklığını,radiusen fazla 5 ondalık basamak içeren kayan noktalı sayı formatında yıldız yarıçapını
içerecek şekilde mydatabase veritabanına ekleyen fonksiyon create_table_Star yer almaktadır. kepler_name bu tablonun ana anahtar sütunudur (PRIMARY KEY). Bu nedenle her bir yıldızın kepler_id adı tek (ing. unique) olmalı ve boş bırakılmamalıdır. Bu yapısıyla PRIMARY KEY her satırı tanımlayan sütun görevini görmektedir.
# Define function to create table
def create_table_Star(cursor):
try:
# Dropping table iris if exists
cursor.execute("DROP TABLE IF EXISTS Star CASCADE;")
sql = '''CREATE TABLE Star (
kepler_id INTEGER NOT NULL,
koi_name VARCHAR(20) NOT NULL,
t_eff INTEGER,
radius FLOAT(5),
PRIMARY KEY (kepler_id)
);'''
# Creating a table
cursor.execute(sql);
print("Star tablosu basariyla olusturulmustur...............")
except psycopg2.OperationalError as err:
# pass exception to function
show_psycopg2_exception(err)
# set the connection to 'None' in case of error
conn = None
Gezegen tablosu Planet da aynı yapıda bir fonksiyonla
kepler_idboş bırakılamayacak (NOT NULL), tamsayıdan oluşan (INTEGER) nesnelerle tanımlanan Kepler katalog ID'lerini,koi_name20 karakter uzunluğunda metin veri saklayabilecek (VARCHAR(20)) ve yine boş bırakılamayacak (NOT NULL) Kepler kataloğu nesene isimlerini,kepler_nameKepler keşfi her bir gezegenin 20 karakter uzunluğunda metin veri saklayabilecek (VARCHAR(20)) ve yine boş bırakılamayacak (NOT NULL) Kepler kataloğundaki isimlerini,statusgezegenin onaylanmış (CONFIRMED) olup olmadığı bilgisini,periodgezegenin kayan noktalı sayı formatında (FLOAT) yörünge dönemini,radiusgezegenin kayan noktalı sayı formatında yarıçapını,t_eqgezegenin tamsayı formatında eşdeğer sıcaklığını,
içerecek şekilde oluşturulmaktadır. Bu fonksiyonun da PRIMARY KEY sütunu kepler_id olarak belirlenmiş ve istenen tablonun oluşturulamaması durumunda oluşacak hata mesajının nasıl yönetileceği belilrlenmiştir.
def create_table_Planet(cursor):
try:
# Dropping table iris if exists
cursor.execute("DROP TABLE IF EXISTS Planet CASCADE;")
sql = '''CREATE TABLE Planet (
kepler_id INTEGER NOT NULL,
koi_name VARCHAR(20),
kepler_name VARCHAR(20),
status VARCHAR(20) NOT NULL,
period FLOAT,
radius FLOAT,
t_eq INTEGER,
PRIMARY KEY (koi_name)
)'''
# Creating a table
cursor.execute(sql);
print("Planet tablosu basariyla olusturulmustur...............")
except psycopg2.OperationalError as err:
# pass exception to function
show_psycopg2_exception(err)
# set the connection to 'None' in case of error
conn = None
Veritabanıyla Bağlantının Kurulması¶
Öncelikle bağlantı için gerekli bilgilerin bir sözlük yapısında tanımlanarak connect fonksiyonuna gönderilmesiyle veritabanıyla bağlantının kurulması sonrası; sırasıyla Star ve Planet tabloları aşağıdaki şekilde oluşturulmaktadır.
conn_params_dic={ 'user':'myuser', 'password':'PostGRE:sql','host':'localhost','dbname':'mydatabase'}
conn = connect(conn_params_dic)
# We set autocommit=True so every command we execute will produce results immediately.
conn.autocommit = True
cursor = conn.cursor()
create_table_Star(cursor)
create_table_Planet(cursor)
PostgreSQL sunucusuna baglaniliyor ........... Baglanti basarili.................. Star tablosu basariyla olusturulmustur............... Planet tablosu basariyla olusturulmustur...............
Veritabanı Tablolarına Verinin Alınması¶
Veritabanındaki tablolara dışarıdan veri almak için öncelikle veriyi içeren dosya data/stars.csv açılmalıdır. Daha sonra bu dosya satır satır okunur ve yapısına bağlı olarak uygun bir şekilde bileşenlerine (sütunlarına) ayrılarak INSERT INTO column_name komutuyla tablonun ilgili sütunlarına alınır.
fn = open("veri/stars.csv")
for line in fn:
f1 = line.split(",")
cursor.execute(
"INSERT INTO Star (kepler_id, koi_name, t_eff, radius) VALUES (%s, %s, %s, %s);",
(f1[0], f1[1], f1[2], f1[3])
)
Planet tablosu da aynı şekilde ilgili dosyadan gelen verilerle aşağıdaki şekilde doldurulabilir.
fn = open("veri/planets.csv")
for line in fn:
f1 = line.split(",")
cursor.execute('''
INSERT INTO Planet (kepler_id, koi_name, kepler_name, status, period, radius, t_eq)
VALUES (%s, %s, %s, %s, %s, %s, %s)
''',(f1[0], f1[1], f1[2], f1[3], f1[4], f1[5], f1[6])
)
SQL Sorgularıyla Satır Seçme¶
Oluşturalan veritabanını sorgulamak üzere bir veya daha fazla tabloyu alan ve istenen verilerle yeni bir tablo döndüren bazı örnekler psycopg2 fonksiyonu cursor.execute ile çalıştırarak aşağıda verilmektedir.
query = "SELECT * FROM Star;"
cursor.execute(query)
sonuc = cursor.fetchall()
for kayit in sonuc:
print(kayit)
(2713049, 'K00794.01', 5996, 0.956) (3114167, 'K00795.01', 5666, 0.677) (3115833, 'K00797.01', 5995, 0.847) (3246984, 'K00799.01', 5735, 0.973) (3342970, 'K00800.01', 6167, 1.064) (3351888, 'K00801.01', 5717, 1.057) (3453214, 'K00802.01', 5733, 0.77) (3641726, 'K00804.01', 5349, 0.82) (3832474, 'K00806.01', 5485, 0.867) (3935914, 'K00809.01', 5934, 0.893) (3940418, 'K00810.01', 5170, 0.807) (4049131, 'K00811.01', 4905, 0.761) (4139816, 'K00812.02', 3887, 0.48) (4275191, 'K00813.01', 5557, 0.781) (4476123, 'K00814.01', 5413, 0.751) (4932348, '', 5575, 0.932) (5358241, 'K00829.01', 6079, 0.945) (5358624, 'K00830.01', 5071, 0.788) (5456651, 'K00835.01', 4980, 0.734) (6862328, 'K00865.01', 5796, 0.871) (6721123, '', 6227, 1.958) (6922244, 'K00010.01', 6225, 1.451) (8395660, 'K00116.01', 5881, 1.029) (9579641, 'K00115.01', 6391, 1.332) (10187017, 'K00082.01', 4812, 0.755) (10480982, 'K00744.01', 6117, 0.947) (10526549, 'K00746.01', 4856, 0.696) (10583066, 'K00747.01', 4536, 0.693) (10601284, 'K00749.01', 5559, 0.806) (10662202, 'K00750.01', 4722, 0.527) (10666592, 'K00002.01', 6350, 1.991) (10682541, 'K00751.01', 5339, 0.847) (10797460, 'K00752.01', 5850, 1.04) (10811496, 'K00753.01', 5853, 0.868) (10419211, '', 5795, 0.848) (10848459, 'K00754.01', 5795, 0.803) (10854555, 'K00755.01', 6031, 1.046) (10583180, '', 4889, 0.819) (10872983, 'K00756.01', 6046, 0.972) (10875245, 'K00117.02', 5851, 1.411) (10910878, 'K00757.01', 5126, 0.742) (10984090, 'K00112.02', 5803, 1.073) (10987985, 'K00758.01', 5015, 0.826) (11018648, 'K00759.01', 5588, 0.796) (11138155, 'K00760.01', 6117, 1.025) (11152159, '', 5550, 0.91) (11153539, 'K00762.01', 6075, 0.969) (11304958, 'K00764.01', 5468, 1.046) (11391957, 'K00765.01', 5592, 0.782) (11403044, 'K00766.01', 6174, 1.103) (11414511, 'K00767.01', 5653, 0.965) (11460018, 'K00769.01', 5641, 0.831) (11446443, 'K00001.01', 5820, 0.964) (11465813, 'K00771.01', 5520, 0.983) (11493732, 'K00772.01', 6144, 1.091) (11507101, 'K00773.01', 5957, 0.971) (11754553, 'K00775.01', 3898, 0.54) (11812062, 'K00776.01', 5492, 0.812) (11818800, 'K00777.01', 5446, 0.781) (11853255, 'K00778.01', 3741, 0.45) (11904151, 'K00072.01', 5627, 1.056) (11918099, 'K00780.01', 4989, 0.727) (11923270, 'K00781.01', 3672, 0.49) (11960862, 'K00782.01', 5992, 0.989) (12020329, 'K00783.01', 5485, 0.867) (12066335, 'K00784.01', 3767, 0.48) (12070811, 'K00785.01', 5557, 0.752) (12110942, 'K00786.01', 5880, 0.917) (12366084, 'K00787.01', 5841, 0.931) (12404086, 'K00788.01', 5127, 0.775) (12470844, 'K00790.01', 5354, 0.788) (12644822, 'K00791.01', 5795, 0.919)
Görüldüğü gibi bu sorgu Star tablosundaki tüm satırları döndürmektedir. SELECT komutu sorguyu başlatmakta * (wildcard) karakteri tüm satırların ("attributes") döndürülmesini sağlamakta; FROM ifadesi ise sorgunun hangi tablo üzerinde uygulanabileceğini belirtmektedir. psycopg2 için zorunlu olmamakla birlikte SQL sorguları ; karakteri ile sonlandırılır.
psycopg2 fonksiyonlarından conn.cursor.execute() sorguyu uygularken cursor.fetchall() sorgunun ürettiği tüm satırları (ing. attributes) alır. Alternatif olarak sadece bir satır alınmak isteniyor ya da sorgunun sadece bir satır ürettiğinden emin olunmuş ise cursor.fetchone() fonksiyonu da kullanılabilir. İstenen sayıda satır almak için cursor.fetchmany() fonksiyonuna satır sayısı argüman olarak geçirilebilir. Tüm bu fonksiyonlar birer liste üretir. Bu liste bir for döngüsü ile taranarak yukarıdaki gibi her satıra (attribute) karşılık gelen demet değişken (tuple) yukarıdaki gibi ayrı ayrı ekrana yazdırılabileceği gibi herhangi bir amaçla ayrılarak da kullanılabilir.
Uyarı: SQL sorguları büyük / küçük harf duyarlı değldir.¶
SQL Sorgularıyla Bazı Satır ve Sütunları Seçme¶
Aşağıdaki sorguyla Star tablosundan bu kez tüm sütunlar yerine sadece koi_name ve radius sütunları seçilmektedir.
query = "SELECT koi_name, radius FROM Star;"
cursor.execute(query)
sonuc = cursor.fetchall()
print("koi_name\t R_*")
for kayit in sonuc:
print(kayit)
koi_name R_*
('K00794.01', 0.956)
('K00795.01', 0.677)
('K00797.01', 0.847)
('K00799.01', 0.973)
('K00800.01', 1.064)
('K00801.01', 1.057)
('K00802.01', 0.77)
('K00804.01', 0.82)
('K00806.01', 0.867)
('K00809.01', 0.893)
('K00810.01', 0.807)
('K00811.01', 0.761)
('K00812.02', 0.48)
('K00813.01', 0.781)
('K00814.01', 0.751)
('', 0.932)
('K00829.01', 0.945)
('K00830.01', 0.788)
('K00835.01', 0.734)
('K00865.01', 0.871)
('', 1.958)
('K00010.01', 1.451)
('K00116.01', 1.029)
('K00115.01', 1.332)
('K00082.01', 0.755)
('K00744.01', 0.947)
('K00746.01', 0.696)
('K00747.01', 0.693)
('K00749.01', 0.806)
('K00750.01', 0.527)
('K00002.01', 1.991)
('K00751.01', 0.847)
('K00752.01', 1.04)
('K00753.01', 0.868)
('', 0.848)
('K00754.01', 0.803)
('K00755.01', 1.046)
('', 0.819)
('K00756.01', 0.972)
('K00117.02', 1.411)
('K00757.01', 0.742)
('K00112.02', 1.073)
('K00758.01', 0.826)
('K00759.01', 0.796)
('K00760.01', 1.025)
('', 0.91)
('K00762.01', 0.969)
('K00764.01', 1.046)
('K00765.01', 0.782)
('K00766.01', 1.103)
('K00767.01', 0.965)
('K00769.01', 0.831)
('K00001.01', 0.964)
('K00771.01', 0.983)
('K00772.01', 1.091)
('K00773.01', 0.971)
('K00775.01', 0.54)
('K00776.01', 0.812)
('K00777.01', 0.781)
('K00778.01', 0.45)
('K00072.01', 1.056)
('K00780.01', 0.727)
('K00781.01', 0.49)
('K00782.01', 0.989)
('K00783.01', 0.867)
('K00784.01', 0.48)
('K00785.01', 0.752)
('K00786.01', 0.917)
('K00787.01', 0.931)
('K00788.01', 0.775)
('K00790.01', 0.788)
('K00791.01', 0.919)
Bir Koşulu Sağlayan Satırları Elde Etme¶
Bazı durumlarda bir tablodan sadece bir koşula uyan bazı sütunlar istenebilir. İsteen sütun adları SELECT ifadesinden sonra verilir ve WHERE ifadesi ile hangi koşula uyan satırların istendiği bir "boolean" ifadeyle veritabanı sunucusuna gönderilir.
query = "SELECT koi_name, radius FROM Star WHERE radius < 2;"
cursor.execute(query)
sonuc = cursor.fetchall()
print("koi_name\t R_*")
for kayit in sonuc:
print(kayit)
koi_name R_*
('K00794.01', 0.956)
('K00795.01', 0.677)
('K00797.01', 0.847)
('K00799.01', 0.973)
('K00800.01', 1.064)
('K00801.01', 1.057)
('K00802.01', 0.77)
('K00804.01', 0.82)
('K00806.01', 0.867)
('K00809.01', 0.893)
('K00810.01', 0.807)
('K00811.01', 0.761)
('K00812.02', 0.48)
('K00813.01', 0.781)
('K00814.01', 0.751)
('', 0.932)
('K00829.01', 0.945)
('K00830.01', 0.788)
('K00835.01', 0.734)
('K00865.01', 0.871)
('', 1.958)
('K00010.01', 1.451)
('K00116.01', 1.029)
('K00115.01', 1.332)
('K00082.01', 0.755)
('K00744.01', 0.947)
('K00746.01', 0.696)
('K00747.01', 0.693)
('K00749.01', 0.806)
('K00750.01', 0.527)
('K00002.01', 1.991)
('K00751.01', 0.847)
('K00752.01', 1.04)
('K00753.01', 0.868)
('', 0.848)
('K00754.01', 0.803)
('K00755.01', 1.046)
('', 0.819)
('K00756.01', 0.972)
('K00117.02', 1.411)
('K00757.01', 0.742)
('K00112.02', 1.073)
('K00758.01', 0.826)
('K00759.01', 0.796)
('K00760.01', 1.025)
('', 0.91)
('K00762.01', 0.969)
('K00764.01', 1.046)
('K00765.01', 0.782)
('K00766.01', 1.103)
('K00767.01', 0.965)
('K00769.01', 0.831)
('K00001.01', 0.964)
('K00771.01', 0.983)
('K00772.01', 1.091)
('K00773.01', 0.971)
('K00775.01', 0.54)
('K00776.01', 0.812)
('K00777.01', 0.781)
('K00778.01', 0.45)
('K00072.01', 1.056)
('K00780.01', 0.727)
('K00781.01', 0.49)
('K00782.01', 0.989)
('K00783.01', 0.867)
('K00784.01', 0.48)
('K00785.01', 0.752)
('K00786.01', 0.917)
('K00787.01', 0.931)
('K00788.01', 0.775)
('K00790.01', 0.788)
('K00791.01', 0.919)
Görüldüğü gibi bu sorgu tüm satırlar arasından sadece koşulu sağlayan (Güneş yarıçapı biriminde 2 Güneş yarıçapından küçük) yıldızları getirmiştir.
Örnek 1: Büyük Yıldızlar¶
Star tablosunda Güneş'ten büyük yıldızların yarıçapını ve sıcaklığını bulmak için bir SQL sorgusu yazınız. Tabloda yıldızların yarıçapı Güneş yarıçapı cinsinden verilmiştir.
cursor.execute("SELECT {:s} FROM {:s} WHERE {:s}".
format("radius,t_eff","Star","radius > 1"))
print(cursor.fetchall())
[(1.064, 6167), (1.057, 5717), (1.958, 6227), (1.451, 6225), (1.029, 5881), (1.332, 6391), (1.991, 6350), (1.04, 5850), (1.046, 6031), (1.411, 5851), (1.073, 5803), (1.025, 6117), (1.046, 5468), (1.103, 6174), (1.091, 6144), (1.056, 5627)]
Şartlı Sorgular¶
SQL'de karşılaştırmalar için $><$, $>$, $\le$, $\ge$ gibi Boolean operatörlerin yanı sıra AND, OR, NOT gibi koşulları birleştirme işlevi taşıyan operatörler de kullanılır.
SELECT ifadesiyle basit bir örnek aşağıdaki şekilde verilebilir.
cursor.execute("SELECT 2 > 3;")
print(cursor.fetchone())
cursor.execute("SELECT NOT 2 > 3;")
print(cursor.fetchone())
cursor.execute("SELECT 2 = 3;")
print(cursor.fetchone())
(False,) (True,) (False,)
Sayısal karşılaştırma operatörleri, tırnak işaretleri kullanılarak verilen metin değişkenlerle de çalışır:
cursor.execute("SELECT 'abc' < 'abcd';")
print(cursor.fetchone())
(True,)
cursor.execute("SELECT 'abc' = 'ABC';")
print(cursor.fetchone())
(False,)
SQL büyük/küçük harfe duyarlı olmasa da metin değişkenler öyle değildir. Bir öznitelikte büyük mü yoksa küçük harflerin mi kullanıldığından emin olunamayan durumlarda, özniteliği dönüştürmek için UPPER veya LOWER işlevi kullanılabilir ve ardından karşılaştırma gerçekleştirilebilir:
cursor.execute("SELECT UPPER('aBc') = 'ABC';")
print(cursor.fetchone())
(True,)
cursor.execute("SELECT LOWER('aBc') = 'abc';")
print(cursor.fetchone())
(True,)
Koşulların Bağlanması¶
Bir WHERE ifadesi içindeki koşullar da birbirlerine AND ve OR ile bağlanabilir.
cursor.execute("SELECT 0 < 1 AND 1 < 2;")
print(cursor.fetchone())
(True,)
Bu özellik veri üzerinde daha komplike sorgular kurgulamak için kullanılır.
cursor.execute('''
SELECT koi_name, radius FROM Star
WHERE radius >= 1 AND radius <= 2;
''')
sonuc = cursor.fetchall()
print("koi_name\t R_*")
for kayit in sonuc:
print(kayit)
koi_name R_*
('K00800.01', 1.064)
('K00801.01', 1.057)
('', 1.958)
('K00010.01', 1.451)
('K00116.01', 1.029)
('K00115.01', 1.332)
('K00002.01', 1.991)
('K00752.01', 1.04)
('K00755.01', 1.046)
('K00117.02', 1.411)
('K00112.02', 1.073)
('K00760.01', 1.025)
('K00764.01', 1.046)
('K00766.01', 1.103)
('K00772.01', 1.091)
('K00072.01', 1.056)
Bu tür aralık sorguları SQL'de yaygın olarak kullanıldığı için SQL bu amaçla BETWEEN ifadesini sağlamıştır. Bu ifade kullanılarak okunması daha kolay sorgular yazılabilir:
cursor.execute('''
SELECT koi_name, radius, t_eff FROM Star
WHERE radius BETWEEN 1 AND 2;
''')
sonuc = cursor.fetchall()
print("koi_name, R_*, T_eff")
for kayit in sonuc:
print(kayit)
koi_name, R_*, T_eff
('K00800.01', 1.064, 6167)
('K00801.01', 1.057, 5717)
('', 1.958, 6227)
('K00010.01', 1.451, 6225)
('K00116.01', 1.029, 5881)
('K00115.01', 1.332, 6391)
('K00002.01', 1.991, 6350)
('K00752.01', 1.04, 5850)
('K00755.01', 1.046, 6031)
('K00117.02', 1.411, 5851)
('K00112.02', 1.073, 5803)
('K00760.01', 1.025, 6117)
('K00764.01', 1.046, 5468)
('K00766.01', 1.103, 6174)
('K00772.01', 1.091, 6144)
('K00072.01', 1.056, 5627)
BETWEEN sorguları aranan aralığın ($1 \le R_{\star} \le 2$) her iki ucunu da dahil ederek sonuç üretirler.
Örnek 2: Sıcak Yıldızlar¶
Star tablosunda etkin sıcaklıkları 5000 ile 6000 K arasında olan tüm yıldızların kepler_id ve t_eff sütunundaki bilgileri getiren bir sorgu yazınız.
# Solution
cursor.execute("SELECT {:s} FROM {:s} WHERE {:s} BETWEEN {:d} AND {:d};".
format("kepler_id, t_eff","Star","t_eff", 5000, 6000))
print("Kepler ID, T_eff")
for kayit in sonuc:
print(kayit)
Kepler ID, T_eff
('K00800.01', 1.064, 6167)
('K00801.01', 1.057, 5717)
('', 1.958, 6227)
('K00010.01', 1.451, 6225)
('K00116.01', 1.029, 5881)
('K00115.01', 1.332, 6391)
('K00002.01', 1.991, 6350)
('K00752.01', 1.04, 5850)
('K00755.01', 1.046, 6031)
('K00117.02', 1.411, 5851)
('K00112.02', 1.073, 5803)
('K00760.01', 1.025, 6117)
('K00764.01', 1.046, 5468)
('K00766.01', 1.103, 6174)
('K00772.01', 1.091, 6144)
('K00072.01', 1.056, 5627)
Bir Veritabanının Yapısının İncelenmesi¶
Bir tabloyu sorgulamak için tablonun yapısının, sütunların adlarının ve ne tür bilgi içerdiklerinin bilinmesi gerekir. Bu amaçla SQL \d (description) komutundan faydalanır. Örneğin PostgreSQL prompt'una (psql) aşağıdaki ifade yazılarak Planet tablosunun yapısı öğrenilebilir.
\d Planet;
psql \d komutu gibi kısayollar sağlasa da bunlar SQL'in parçası değildirler.. psycopg2 ile sorgularda SQL'de bu amaçla kullanılan information_schema özniteliğinden aşağıdaki şekilde faydalanılır.
cursor.execute('''
SELECT column_name, data_type, is_nullable
FROM information_schema.columns
WHERE table_name = %s;
''',("planet",))
for column in cursor.fetchall():
print(column)
('period', 'double precision', 'YES')
('radius', 'double precision', 'YES')
('t_eq', 'integer', 'YES')
('kepler_id', 'integer', 'NO')
('status', 'character varying', 'NO')
('koi_name', 'character varying', 'NO')
('kepler_name', 'character varying', 'YES')
information_schema (ya da \d) her sütunun adını, ne tür veri sakladığını ve NULL veri içerip içeremeyeceği gibi bilgiler döndürür. Elde edilebilecek diğer bilgiler için bkz.
Bazı sütunların NULL türünde veri içeremeyeceği görülmektedir. Bu konu önemli olduğundan kısaca bakmakta fayda vardır.
SQL'de NULL Değeri¶
Daha önceki derslerden bilindiği gibi NULLözel bir veri türüdür. Örnek olarak verilen Planet tablosunda tüm ötegezegnlerin kepler_name sütunları dolu değildir. Zira tüm gezegenler diğer yöntemlerle onaylanarak CONFIRMED statüsü almamış olabilir. Bu sütunlar NULL değeri alabilir. Ancak tüm çalışılan cisimlerin tekil birer (ing. unique) kepler_id numaraları bulunduğundan değerleri NULL olamaz.
NULL ile boşluk ' ' aynı anlama gelmez:
cursor.execute("SELECT '' = NULL;")
print(cursor.fetchone())
(None,)
Bu karşılaştırma SQL tarafından yapılamadığından False ya da True yerine None değeri döndürmüştür. Çünkü SQL tarafından NULL değeri bilinmemektedir. Ancak IS karşılaştırması yapılarak istenen amaca ulaşılabilir.
cursor.execute("SELECT NULL IS NULL;")
print(cursor.fetchone())
(True,)
Bununla, $=$ operatörüne sahip ilk sorgunun aslında bir $NULL$ değeri döndürdüğünü de görebilirsiniz:
cursor.execute("SELECT ('' = NULL) IS NULL; ")
print(cursor.fetchone())
(True,)
Örnek 3: Onaylanmış Küçük Gezegenler¶
Planet tablosundaki onaylanmış gezegenleri (kepler_name sütunu NULL olmayan ya da status sütunu CONFIRMED olan gezegenler) listeleyen bir SQL sorgusu yazınız. Sorgunuzun sonucunu sadece 1 ile 3 Yer yarıçapı gezegenler arasındakileri alacak şekilde sınırlandırınız. Tabloda gezegen yarıçapları Yer yarıçapı cinsinden verilmiştir.
query = '''
SELECT {} FROM {} WHERE {} = 'CONFIRMED'
AND {} IS NOT NULL
AND {} BETWEEN {} AND {}
'''.format("kepler_name,radius","Planet","status","kepler_name","radius",1,3)
print("Kepler Name, R_p")
cursor.execute(query)
for column in cursor.fetchall():
print(column)
Kepler Name, R_p
('Kepler-10 b', 1.45)
('Kepler-466 c', 1.24)
('Kepler-105 c', 1.88)
('Kepler-106 c', 2.35)
('Kepler-106 e', 2.58)
('Kepler-107 c', 1.84)
('Kepler-660 b', 2.52)
('Kepler-226 c', 2.7)
('Kepler-226 b', 1.59)
('Kepler-226 d', 1.19)
('Kepler-662 b', 1.54)
('Kepler-663 b', 2.7)
('Kepler-664 b', 2.71)
('Kepler-228 b', 1.56)
('Kepler-229 b', 2.41)
('Kepler-665 b', 2.86)
('Kepler-230 c', 2.13)
('Kepler-666 b', 2.21)
('Kepler-668 b', 2.54)
('Kepler-671 b', 2.33)
('Kepler-672 b', 2.7)
('Kepler-52 c', 1.81)
('Kepler-52 b', 2.33)
('Kepler-52 d', 1.8)
('Kepler-674 b', 1.32)
('Kepler-675 b', 2.38)
('Kepler-231 c', 1.73)
('Kepler-231 b', 1.61)
('Kepler-679 b', 2.69)
('Kepler-680 b', 1.96)
('Kepler-233 b', 2.71)
('Kepler-233 c', 2.72)
('Kepler-683 b', 1.97)
('Kepler-684 b', 2.66)
('Kepler-30 b', 1.91)
('Kepler-235 b', 2.18)
('Kepler-235 d', 1.99)
('Kepler-235 e', 1.94)
('Kepler-235 c', 1.22)
('Kepler-689 b', 2.45)
('Kepler-53 b', 2.9)
('Kepler-53 d', 2.44)
('Kepler-239 b', 2.36)
('Kepler-239 c', 2.19)
SQL'de Veri İstatistikleri ve Birleştirme Fonksiyonları¶
COUNT Fonksiyonu¶
Veritabanlarının boyutu büyüdükçe, istenen tüm verilerin tam bir tablosunu yazdırmak artık öğretici ve hatta mümkün olmayabilir. Bu durumlarda sonuçları sınırlandırmak için sorguyu daha spesifik hale getirme yoluna gidilebilir. Ancak hangi sonuçların beklendiği önceden bilinmiyorsa, verilerin boyutunu ve istatistiklerini karakterize etmek ve listelenen verileri sınırlandırmak için daha iyi bir yola ihtiyaç duyulur.
İstenen verileri tablo formatında döndürmek yerine, yalnızca sonuç tablosundaki satır sayısını döndürmek için COUNT fonksiyonu kullanılabilir. Örneğin Planet tablosundaki tüm gezegenleri saymak için bir örnek aşağıda verilmiştir.
cursor.execute("SELECT COUNT(*) FROM Planet;")
print(cursor.fetchone())
(96,)
COUNT daha önce görülen diğer tüm SQL ifadeleriyle birleştirilebilir. Örneğin yalnızca onaylanmış gezegenlerin sayısını almak için aşağıdaki gibi bir sorgu yazılabilir.
query = '''
SELECT COUNT(*) FROM {}
WHERE {} IS NOT NULL;
'''.format('Planet','kepler_name')
cursor.execute(query)
print(cursor.fetchall())
[(96,)]
Diğer Birleştirme ve İstatistik Fonksiyonları¶
COUNT SQL'in veri birleştirme (ing. aggregate) fonksiyonlarından yalnızca biridir. Bu tür fonksiyonlar yalnızca bir sonuç döndürdüğünden psycopg2 'de cursor.fetchone() fonksiyonuyla içerikleri bir demet değişkene (tuple) alınabilir. SQL
SQL'in sunduğu diğer birleştirme ve istatistik fonksiyonlarında en çok kullanılan bazıları aşağıda listelenmiştir. Bu fonksiyonların hangi veriler veya hangi veri aralığına uygulanacağını bilmek, bir sorguyu daha spesifik hale getirmeye yardımcı olabilir.
| Fonksiyon | Çıktı | |
|---|---|---|
| COUNT | Sorgu sonucu döndürülecek satır sayısı | |
| MIN | Bir sütundaki minimum değer | |
| MAX | Bir sütundaki maksimum değer | |
| SUM | Bir sütundaki değerlerin toplamı | |
| AVG | Bir sütundaki değerlerin ortalaması | |
| STDDEV | Bir sütundaki değerlerin standart sapması |
Bu fonksiyonların kullanımına ilişkin bazı örnekler aşağıda sunulmuştur.
query = '''
SELECT MIN({}), MAX({}), AVG({})
FROM {};
'''.format('radius','radius','radius','Planet')
cursor.execute(query)
print(cursor.fetchone())
(0.49, 3791.05, 85.74760416666668)
SELECT ifadesinde SUM ve bölme (/) operatörlerini birlikte kullanarak AVG fonksiyonunun sonucuyla karşılaştırmak için aşağıdaki gibi bir sorgu yazılabilir.
query = '''
SELECT SUM({})/COUNT(*), AVG({})
FROM {};
'''.format('t_eff','t_eff','Star')
cursor.execute(query)
print(cursor.fetchone())
(5503, Decimal('5503.3472222222222222'))
Bu iki sonucun birbirinden farklı olmasının nedeni t_eff özniteliğinin bir tamsayı olması ve SQL 'in "/" operatörüyle bu özniteliği içeren bölme işlemlerini tamsayı bölmesi şeklinde yapmasıdır. SQL'de tam sayı bölmesi aşağıdaki şekilde uygulanır. SQL'de "/" operatörüyle uygulanan bölme işlemi bu yapısyla Python 2.x versiyonlarındakine benzer şekilde çalışır.
query = "SELECT 1/2, 1/2.0"
cursor.execute(query)
print(cursor.fetchone())
(0, Decimal('0.50000000000000000000'))
Sorgu Sonuçlarını Sıralama ve Limitleme¶
Bir sorgu sonucunda elde edilen tablodaki sonuçlar yararlı bir şekilde sıralanmış olmayabilir; zira veritabanındaki girildikleri sırayla getirilirler.
ORDER BY fonksiyonu istenen bir sütuna dayalı olarak istenen sırada sonuçların sıralanmasını sağlar. Örneğin Planet tablosundaki bir sorgunun gezegen yarıçapına (radius) azalan sırada (descending -- DESC) sıralanması için aşağıdaki sorgu yazılabilir.
query = '''
SELECT {} FROM {}
ORDER BY {} DESC;
'''.format("koi_name, radius", "Planet", "radius")
print("KOI Numarasi, Yaricap (Yer Yaricapi)")
cursor.execute(query)
for record in cursor.fetchall():
print(record)
KOI Numarasi, Yaricap (Yer Yaricapi)
('K00759.01', 3791.05)
('K00753.01', 3462.25)
('K00799.01', 447.32)
('K00772.01', 64.23)
('K00744.01', 51.4)
('K00754.01', 34.04)
('K00002.01', 16.39)
('K00010.01', 14.83)
('K00771.01', 14.41)
('K00806.02', 12.88)
('K00001.01', 12.85)
('K00767.01', 12.82)
('K00802.01', 12.0)
('K00760.01', 11.88)
('K00830.01', 11.87)
('K00809.01', 11.77)
('K00801.01', 9.74)
('K00806.01', 9.36)
('K00797.01', 8.18)
('K00777.01', 8.02)
('K00813.01', 7.92)
('K00791.01', 7.66)
('K00865.01', 7.58)
('K00776.01', 6.27)
('K00764.01', 5.73)
('K00782.01', 5.38)
('K00780.02', 5.32)
('K00757.01', 5.27)
('K00783.01', 4.91)
('K00766.01', 4.46)
('K00756.01', 4.02)
('K00787.02', 3.74)
('K00800.01', 3.62)
('K00757.02', 3.62)
('K00811.01', 3.62)
('K00829.03', 3.57)
('K00800.02', 3.51)
('K00115.01', 3.28)
('K00788.01', 3.16)
('K00747.01', 3.14)
('K00752.02', 3.1)
('K00752.01', 3.1)
('K00781.01', 3.07)
('K00787.01', 3.07)
('K00756.02', 3.02)
('K00829.01', 2.9)
('K00758.01', 2.86)
('K00810.01', 2.76)
('K00804.01', 2.72)
('K00790.02', 2.72)
('K00790.01', 2.71)
('K00755.01', 2.71)
('K00773.01', 2.7)
('K00749.01', 2.7)
('K00751.01', 2.7)
('K00785.01', 2.69)
('K00795.01', 2.66)
('K00116.02', 2.58)
('K00765.01', 2.54)
('K00746.01', 2.52)
('K00814.01', 2.45)
('K00829.02', 2.44)
('K00757.03', 2.41)
('K00780.01', 2.38)
('K00835.01', 2.36)
('K00116.01', 2.35)
('K00775.02', 2.33)
('K00769.01', 2.33)
('K00762.01', 2.21)
('K00835.02', 2.19)
('K00812.01', 2.18)
('K00759.02', 2.13)
('K00812.02', 1.99)
('K00794.01', 1.97)
('K00786.01', 1.96)
('K00812.03', 1.94)
('K00806.03', 1.91)
('K00115.02', 1.88)
('K00117.02', 1.84)
('K00775.01', 1.81)
('K00775.03', 1.8)
('K00784.01', 1.73)
('K00784.02', 1.61)
('K00749.02', 1.59)
('K00756.03', 1.56)
('K00750.01', 1.54)
('K00072.01', 1.45)
('K00778.01', 1.32)
('K00112.02', 1.24)
('K00812.04', 1.22)
('K00749.03', 1.19)
('K00116.04', 0.99)
('K00116.03', 0.85)
('K00115.03', 0.65)
('K00082.04', 0.58)
('K00082.05', 0.49)
Görüldüğü gibi tablo çok uzundur. Bu tablonun sadece bir kısmını görmek için LIMIT fonksiyonu kullanılabilir. Örneğin en küçük 5 gezegeni listelemek için azalan sıra (DESC) yerine artan sırada (ASC) sıralama istenerek sorgu sonuçları aşağıdaki şekilde limitlenebilir.
query = '''
SELECT {} FROM {}
ORDER BY {} ASC
LIMIT 5;
'''.format("koi_name, radius", "Planet", "radius")
print("KOI Numarasi, Yaricap (Yer Yaricapi)")
cursor.execute(query)
for record in cursor.fetchall():
print(record)
KOI Numarasi, Yaricap (Yer Yaricapi)
('K00082.05', 0.49)
('K00082.04', 0.58)
('K00115.03', 0.65)
('K00116.03', 0.85)
('K00116.04', 0.99)
Bu tür bir sınırlandırma büyük tablolarla karşılaşıldığında performansı önemli ölçüde etkileyecektir.
Örnek 4: Gezegen İstatistikleri¶
Onaylanmış gezegenler için
- minimum yarıçap;
- maksimum yarıçap;
- ortalama yarıçap ve
- yarıçapın standart sapma değerlerini
veren bir SQL sorgusu yazınız.
query = '''
SELECT MIN(radius),MAX(radius),AVG(radius),STDDEV(radius)
FROM Planet WHERE status IS NOT NULL
'''
print("Minimum, Maksimum, Ortalama, St.Sapma")
cursor.execute(query)
for record in cursor.fetchall():
print(record)
Minimum, Maksimum, Ortalama, St.Sapma (0.49, 3791.05, 85.74760416666668, 521.7809005819341)
Veriyi Gruplama¶
Planet tablosunda aynı boyuta sahip (eşit yarıçaplı) birden fazla gezegen olup olmadığı öğrenilmek isteniyor olsun. Bu amaçla sonuçları aynı yarıçapın birden çok kez geçtiği gezegenleri görmek üzere sıralanmış basit bir sorgu yazılabilir.
query = '''
SELECT {} FROM {}
ORDER BY {} ASC;
'''.format('kepler_id, radius','Planet','radius')
cursor.execute(query)
print("Kepler ID, Yaricap")
for record in cursor.fetchall():
print(record)
Kepler ID, Yaricap (10187017, 0.49) (10187017, 0.58) (9579641, 0.65) (8395660, 0.85) (8395660, 0.99) (10601284, 1.19) (4139816, 1.22) (10984090, 1.24) (11853255, 1.32) (11904151, 1.45) (10662202, 1.54) (10872983, 1.56) (10601284, 1.59) (12066335, 1.61) (12066335, 1.73) (11754553, 1.8) (11754553, 1.81) (10875245, 1.84) (9579641, 1.88) (3832474, 1.91) (4139816, 1.94) (12110942, 1.96) (2713049, 1.97) (4139816, 1.99) (11018648, 2.13) (4139816, 2.18) (5456651, 2.19) (11153539, 2.21) (11460018, 2.33) (11754553, 2.33) (8395660, 2.35) (5456651, 2.36) (11918099, 2.38) (10910878, 2.41) (5358241, 2.44) (4476123, 2.45) (10526549, 2.52) (11391957, 2.54) (8395660, 2.58) (3114167, 2.66) (12070811, 2.69) (10682541, 2.7) (10601284, 2.7) (11507101, 2.7) (10854555, 2.71) (12470844, 2.71) (12470844, 2.72) (3641726, 2.72) (3940418, 2.76) (10987985, 2.86) (5358241, 2.9) (10872983, 3.02) (12366084, 3.07) (11923270, 3.07) (10797460, 3.1) (10797460, 3.1) (10583066, 3.14) (12404086, 3.16) (9579641, 3.28) (3342970, 3.51) (5358241, 3.57) (3342970, 3.62) (10910878, 3.62) (4049131, 3.62) (12366084, 3.74) (10872983, 4.02) (11403044, 4.46) (12020329, 4.91) (10910878, 5.27) (11918099, 5.32) (11960862, 5.38) (11304958, 5.73) (11812062, 6.27) (6862328, 7.58) (12644822, 7.66) (4275191, 7.92) (11818800, 8.02) (3115833, 8.18) (3832474, 9.36) (3351888, 9.74) (3935914, 11.77) (5358624, 11.87) (11138155, 11.88) (3453214, 12.0) (11414511, 12.82) (11446443, 12.85) (3832474, 12.88) (11465813, 14.41) (6922244, 14.83) (10666592, 16.39) (10848459, 34.04) (10480982, 51.4) (11493732, 64.23) (3246984, 447.32) (10811496, 3462.25) (11018648, 3791.05)
Ancak bu tür bir tabloda birden fazla kez geçen yarıçap değeri bulmak zor olduğu gibi tablonun daha büyük olması durumunda olanaksız hale de gelebilir. Böyle durumlarda GROUP BY fonksiyonundan yararlanarak birbiriyle aynı bilgiler üzerindne gruplandırmalar yapılarak sayma (COUNT) gibi birleştirme fonksiyonlarından faydalanılabilir. Bir önceki sorguda karşılaşılan problem aşağıdaki gibi bir sorguyla çözülebilir.
query = '''
SELECT {}, COUNT({})
FROM {}
GROUP BY {};
'''.format('radius','koi_name','Planet','radius')
print("Yaricap, Sayi")
cursor.execute(query)
for record in cursor.fetchall():
print(record)
Yaricap, Sayi (2.52, 1) (2.76, 1) (5.38, 1) (2.41, 1) (2.36, 1) (12.85, 1) (1.32, 1) (3.14, 1) (6.27, 1) (2.71, 2) (3.57, 1) (7.92, 1) (2.44, 1) (8.02, 1) (2.9, 1) (14.83, 1) (7.58, 1) (8.18, 1) (5.27, 1) (2.58, 1) (1.81, 1) (2.45, 1) (3.74, 1) (12.0, 1) (2.66, 1) (4.02, 1) (1.88, 1) (14.41, 1) (16.39, 1) (3.16, 1) (4.91, 1) (11.88, 1) (4.46, 1) (2.86, 1) (3.02, 1) (2.19, 1) (3.28, 1) (1.56, 1) (2.54, 1) (0.49, 1) (1.8, 1) (2.35, 1) (3462.25, 1) (447.32, 1) (1.96, 1) (51.4, 1) (12.82, 1) (1.99, 1) (0.65, 1) (3.1, 2) (1.24, 1) (2.38, 1) (0.85, 1) (1.91, 1) (1.54, 1) (2.7, 3) (2.33, 2) (11.87, 1) (7.66, 1) (2.13, 1) (12.88, 1) (2.18, 1) (2.72, 2) (3.62, 3) (2.21, 1) (1.73, 1) (1.22, 1) (1.61, 1) (1.59, 1) (3.51, 1) (64.23, 1) (9.74, 1) (9.36, 1) (5.73, 1) (34.04, 1) (11.77, 1) (0.99, 1) (1.45, 1) (0.58, 1) (2.69, 1) (1.94, 1) (5.32, 1) (1.97, 1) (3791.05, 1) (1.84, 1) (3.07, 2) (1.19, 1)
Bu sorgu bir öncekine göre daha faydalı, ancak hala çok uzundur. Bu sorgunun sonuçlarını daha da sınırlandırmakta fayda vardır.
Gruplandırılmış Veride Şartlı Sorgulama¶
Bu sorgunun sonucundaki tabloyu gezegen sayısının birden büyük olduğu sonuçlarla sınırlamak istendiğinde, WHERE ifadesi kullanılarak bir koşul eklenebilir. Aşağıdaki sorgu bu amaç için ilk bakışta ideal gözükebilir:
SELECT radius, COUNT(koi_name)
FROM Planet
WHERE COUNT(koi_name) > 1
GROUP BY radius;
Ancak WHERE ifadesi GROUP BY fonksiyonundan önce geçtiği için gruplandırılmış tablounun COUNT fonsiyonuna erişimi kalmamıştır.
COUNT gibi birleştirme fonksiyonlarına GROUP BY ifadeleriyle gruplanan tabloların erişimi içinWHERE yerine HAVING ifadesi kullanılır.
query = '''
SELECT {}, COUNT({})
FROM {}
GROUP BY {}
HAVING COUNT({}) > {};
'''.format('radius','koi_name','Planet','radius','koi_name',1)
cursor.execute(query)
for record in cursor.fetchall():
print(record)
(2.71, 2) (3.1, 2) (2.7, 3) (2.33, 2) (2.72, 2) (3.62, 3) (3.07, 2)
Örnek 5: Çoklu Gezegen Sistemleri¶
Planet tablosunda yer alan çok gezegenli sistemlerdeki gezegen sayısını verecek bir sorgu yazınız. Aynı barınak yıldızın etrafında dolanan gezegenler aynı kepler_id değerine, ancak farklı koi_name değerlerine sahip olacaktır.
Sorgunuz, her satırda yıldızın kepler_id değerini ve o yıldızın etrafında dönen gezegenlerin sayısını (yani bu kepler_id değerini paylaşan gezegenlerin sayısını) içeren bir tablo döndürmelidir.
Sonuçlarınız sadece çoklu gezegen sistemleri (birden fazla gezegen içeren) sıralanmış olmalıı ve artan gezegen sayısına göre sıralanmalıdır.
query = '''
SELECT {}, COUNT({}) FROM {}
GROUP BY {}
HAVING COUNT({}) > {}
ORDER BY COUNT({}) DESC;
'''.format('kepler_id','koi_name','Planet','kepler_id','koi_name',1,'koi_name')
print("Kepler ID, Gezegen Sayisi")
cursor.execute(query)
for record in cursor.fetchall():
print(record)
Kepler ID, Gezegen Sayisi (8395660, 4) (4139816, 4) (3832474, 3) (5358241, 3) (10910878, 3) (9579641, 3) (10872983, 3) (10601284, 3) (11754553, 3) (12066335, 2) (11918099, 2) (10797460, 2) (12366084, 2) (3342970, 2) (11018648, 2) (10187017, 2) (5456651, 2) (12470844, 2)