k-d Ağaçları¶
Çapraz eşleştirme, astronomide sıklıkla yapıaln bir işlem olduğundan optimize edilmiş uygulamalarının zaten kodlanmış olması doğaldır. Astropy modülü k-d ağaçlarına dayalı bir çapraz korelasyon fonksiyonunu bu amaçla sunmaktadadır.
Astropy, içinde arama yapılan ikinci katalogdan bir k-d ağacı oluşturarak, ilk katalogdaki her cisim için ikili aramaya benzer bir şekilde bir eşleşme arar. Bu algoritmada k-boyutlu uzay, her seferinde bölümün bir tarafı yalnızca tek bir cisim içerene kadar özyinelemeli (recursive) olarak iki parçaya bölünür.
Katalog eşleştirme uygulamasında bu algoritma;
Sağaçıklığın ortanca (medyan) değerini bul, kataloğu bunun sağı ve solundan ikiye böl.
Her bölümde deklinasyonun ortanca değerini bul, bölümü bunun aşağı ve yukarısından ikiye böl.
Bu bölümlerin her birinde sağaçıklığın ortanca (medyan) değerini bul, bu bölümü bunun sağı ve solundan ikiye böl.
2 ve 3. adımları her bölümde tek bir nesne kalıncaya kadar sürdür.
Bu algoritma içinde arama yapılacak aşağıdaki şekilde bir ikili ağaç oluşturur.
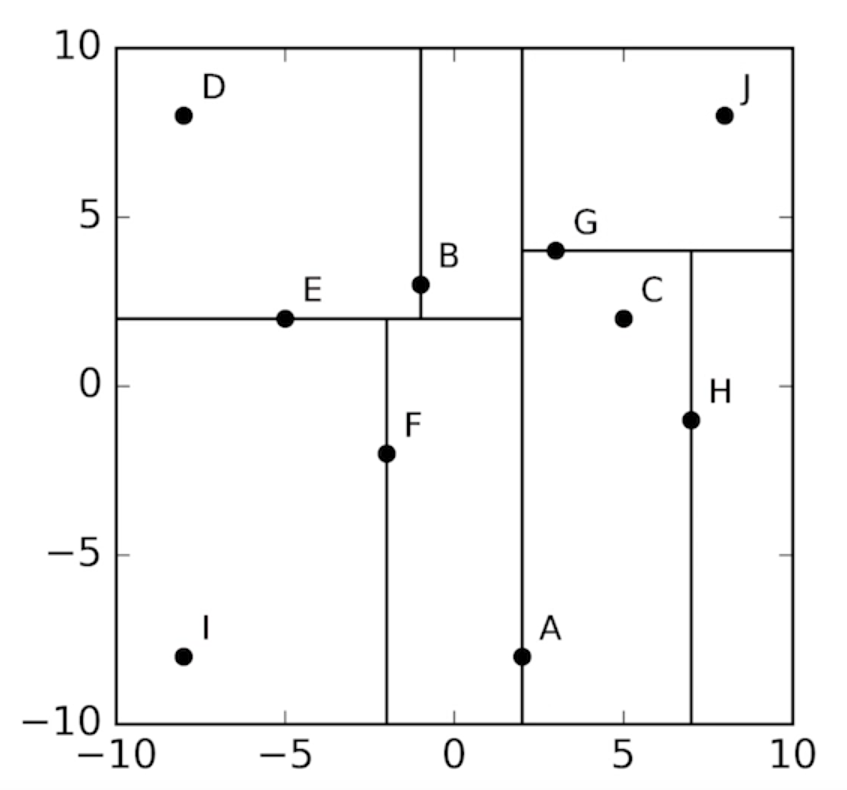
Yukarıdaki şekilde 10 cisimden 6. sı olan $A$ sağ açıklıktaki medyan (ortanca) olarak seçilebilir (5 de seçilebilirdi ama sağdaki (daha büyük sağ açıklık değerine sahip olan tercih edilir.). Buradan yapılacak bir bölme sonrası, bu değerin sol ya da sağ tarafına geçilerek ilerlenebilir. Sol tarafa geçilecek olunursa oradaki 5 koordinatın deklinasyonda ortancası $E$'dir. Buradan bölündükten sonra üst ya da alt tarafa geçilerek devam edilebilir. Bu bölmenin üst tarafına geçilecek olursa iki koordinat kaldığı görülür ($D$,$B$); medyan olarak bunlardan sağ açıklığı büyük olan $B$ koordinatı seçilir. Burada deklinasyon ekseninde ilerlenebilecek bir düğüm kalmamıştır; zira $D$ tek başınadır ve alt bölmeye geçilir. Alt bölmenin sağ açıklıktaki medyanı sağ açıklığı büyük olan $F$ olarak belirlenir. Daha sonra $A$'nın sağ tarafına geçilir. Bu bölmede bulunan 4 koordinattan deklinasyonda daha büyük olan $G$ medyan olarak belirlenir. Bunun üzerinde tek bir nokta kalmış olduğundan alt bölmeye inilir ve sağ açıklıkta daha büyük olan $H$ medyan olarak belirlenir. Bunun sol tarafında sadece bir koordinat kaldığından ağaç yapısı tamamlanmış olur.
k-d Ağaçları İçinde Arama¶
k-d ağacı oluşturulduktan sonra arama aşağıdaki şekilde yapılır.
Aranan cisimle en yüksek seviyedeki düğüm (kök düğüm) arasındaki uzaklığı hesapla, ardından bu düğüme sağ açıklıkta en yakın alt düğüme git,
Aranan cisimle bu düğümdeki (child) cisim arasındaki uzaklığı hesapla, ardından bu alt düğüme dik açıklıkta en yakın alt düğüme git,
Arnanan cisimle bu düğümdeki (child) cisim arasındaki uzaklığı hesapla, ardından alt düğüme sağ açıklıkta en yakın alt düğüme git,
2-3 arasındaki adımları artık alt düğüm (child) kalmayıncaya kadar tekrarla ve en alt düğüme (leaf node) ulaş,
Hesaplanan tüm uzaklıkların en kısasını bul, bu uzaklık aranan cisme ikinci katalogdaki en yakın cismin uzaklığıdır.
Her bir düğüm iki "çocuk" düğüme ayrıldığı için
$N$ cisim için "kökten" (root) "yaprağa" (leaf) $log_2(N) $ düğümde inilir. Bu şekilde SuperCOSMOS kataloğu gibi 250 million cisim içeren bir kataloda yalnız 28 uzaklık hesabı yeterli olmaktadır!
Aşağıdaki şekilde koordinatları bilinen $T$ cismine k-d ağacına dönüştürülen bir katalogdaki en yakın cisim aranmaktadır.
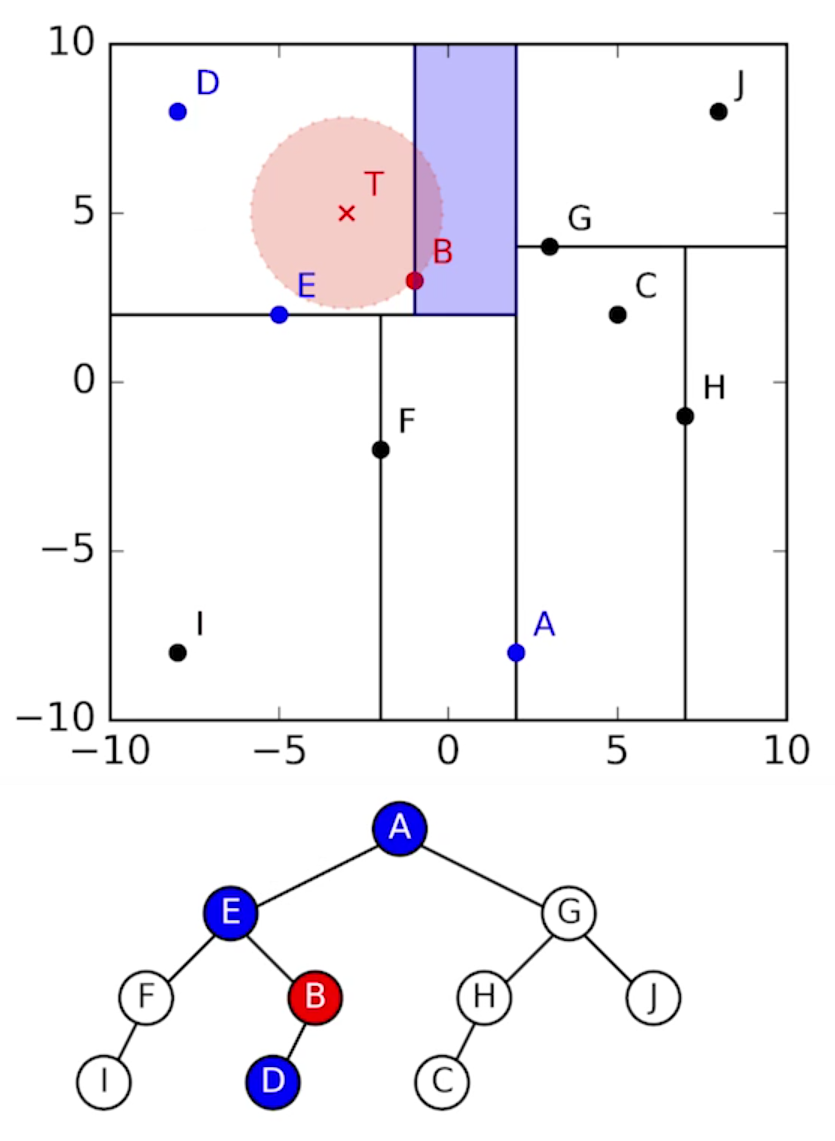
$T$ cismi ile öncelikle kök düğümdeki cisim ($A$) arasındaki uzaklık hesaplanır. Daha sonra $A$'ya sağaçıklıkta en yakın alt düğümdeki cisme ($E$) gidilir ve bununla $T$ cismi arasındaki mesafe hesaplanır. Bu uzaklık $A$'ya uzaklığa göre küçük olduğundan $E$'de kalınır ve $E$'ye deklinasyonda en yakın cismin bulunduğu alt düğüme geçilir. Bu cisim $B$'dir. $B$ ile $T$ arasındaki uzaklık $E$ ile olandan küçüktür ve devam edilir. Bu kez $B$'ye sağ açıklıkça en yakın alt düğüme gidilir. Bu alt düğümde $D$ bulunmaktadır. $D$ ile $T$ arasındaki mesafe $B$ ile olana göre büyüktür. $T$ cismine k-d ağacına dönüştürülmüş katalogdaki en yakın cisim $B$ olarak 4 karşılaştırma 5 uzaklık ölçümü sonrası bulunmuş olur. Eğer bu cisim istenen bir yarıçap içindeyse $T$ cismi ile eşleşen bir cisim olarak değerlendirilebilir.
Astropy ile bu şekilde yapılan bir arama aşağıda örnek olarak verilmiştir.